
کاهش 95 درصدی مصرف VRAM با فناوری جدید Nvidia

انویدیا در سالهای اخیر روی روشی کار کرده که میتواند بافتهای گرافیکی را بهصورت هوشمند فشرده کند و به شکل قابلتوجهی حافظه گرافیکی (VRAM) را کاهش دهد. این فناوری که هنوز در مرحله بتا قرار دارد، در یک دموی جدید قدرت خود را نشان داده و پتانسیل بالایی دارد تا مشکل محدودیت حافظه را که این روزها میان کارتهای گرافیکی مدرن رایج است، برطرف کند. «فشردهسازی عصبی بافت» (Neural Texture Compression) ممکن است کمی پیچیده بهنظر برسد، اما اساس کارش بر یک شبکه عصبی است که بافتهای مختلف را بهصورت پویا فشرده و دوباره از حالت فشرده خارج میکند. این یعنی، بهجای اینکه بازی یا نرمافزار مجبور باشد حجم بالایی از بافتها را بهطور دائمی در حافظه بارگذاری کند، فقط هنگامی که قسمتی از بافت واقعاً مورد نیاز است، آن را از حالت فشرده خارج میکند.
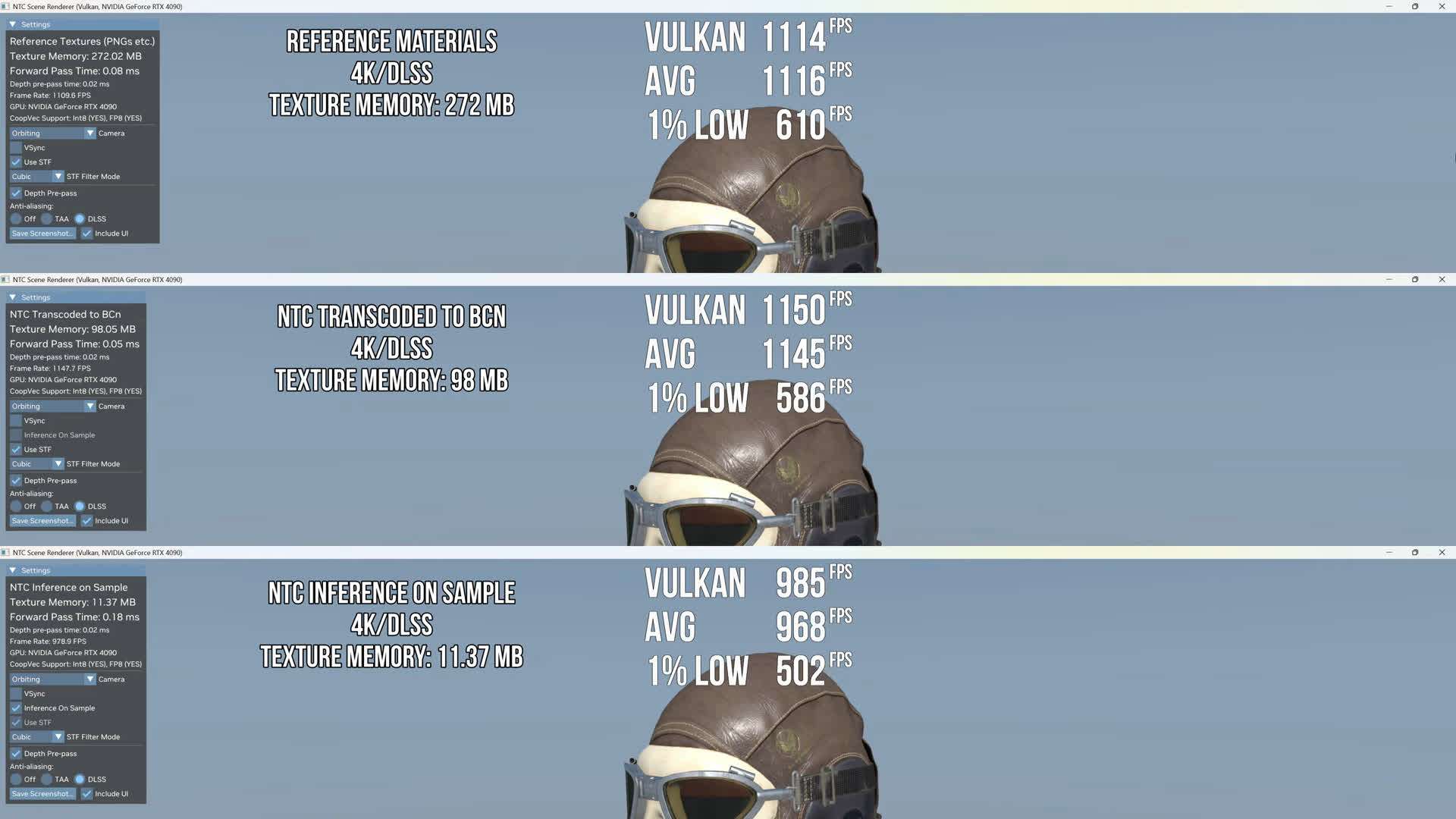
دموی جدیدی که توسط کانال یوتیوب Compusemble تست شده، جزئیات جالبی از این فناوری ارائه میدهد. در این تست، سه حالت رندر بررسی میشود: حالت نخست که از هیچگونه فشردهسازی عصبی استفاده نمیکند و بافتها همانطور که هستند بارگذاری میشوند. حالت دوم از روش NTC و سپس تبدیل این بافتها به فرمتهای بلوکی مرسوم (BCn) بهره میبرد؛ و حالت سوم که هنگام نیاز، بافتها را با استفاده از شبکه عصبی از فشردگی خارج میکند. طبق گزارش، تفاوت اصلی بین این سه حالت در مقدار فضایی است که روی دیسک و بهخصوص روی حافظه گرافیکی اشغال میشود. در حالت سوم، بالاترین سطح صرفهجویی حاصل میشود؛ چراکه بافت فقط وقتی نیاز باشد، «از طریق نمونهگیری» از حالت فشرده خارج میشود و این روند تا 95 درصد میزان استفاده از VRAM را پایین میآورد.

بهعنوان نمونه، در رزولوشن 1440p و استفاده از DLSS، وقتی از روش تبدیلشده به BCn استفاده شد، حافظه گرافیکی از 272 مگابایت به 98 مگابایت کاهش یافت که کاهش 64 درصدی را نشان میدهد. اما وقتی از حالت «استنتاج هنگام نمونهگیری» یا همان Inference on Sample استفاده شد، مصرف حافظه به 11.37 مگابایت رسید؛ عددی که نشان میدهد ما با یک جهش بزرگ در کاهش مصرف VRAM طرف هستیم. البته این صرفهجویی چشمگیر میتواند روی نرخ فریم نیز تأثیر بگذارد، زیرا شبکه عصبی نیاز دارد در لحظه بافت را از حالت فشرده خارج کند و این کار به منابع محاسباتی بیشتری احتیاج دارد. در تستی که روی کارت گرافیک GeForce RTX 4090 انجام شده، استفاده از DLSS و رزولوشنهای بالاتر، فشار بیشتری روی هستههای تنسور (Tensor Cores) وارد کرده و در برخی موارد به افت نسبی فریم منجر شده است.

با این حال، باید توجه داشت که فناوریهای آینده ممکن است به نحوی بهینهسازی شوند که این اختلاف عملکرد ناچیز شود. انویدیا طی سالهای اخیر روی روشهای متنوعی از رندرینگ مبتنی بر هوش مصنوعی سرمایهگذاری کرده و NTC هم قطعاً نقش مهمی در این مسیر دارد. طبیعی است که با عرضه کارتهای نسل جدیدتر و بهبود معماری هستههای تنسور، افت عملکرد به حداقل برسد و در عین حال، صرفهجویی عظیم در حافظه گرافیکی و فضای دیسک همچنان حفظ شود.
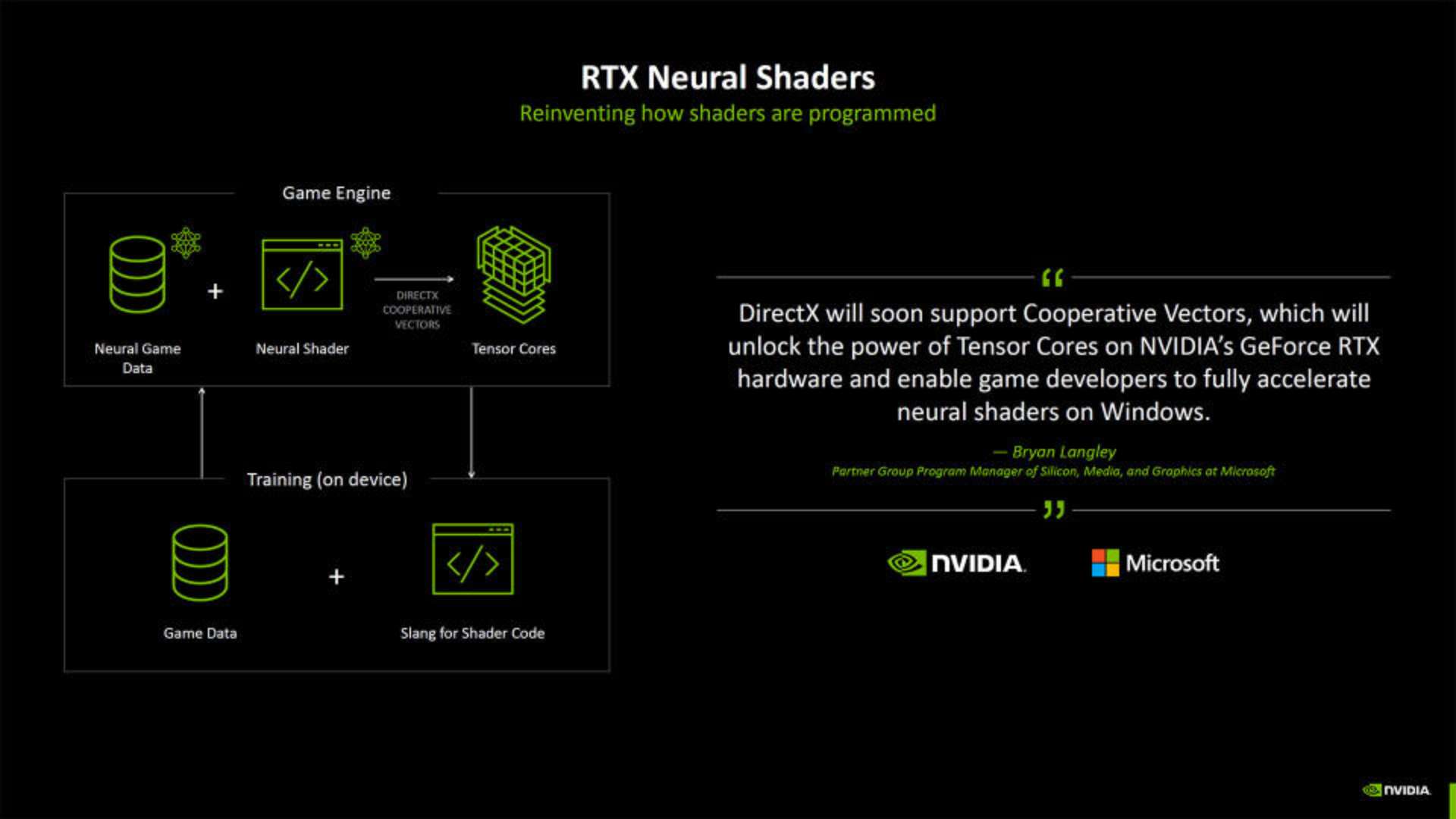
نکته دیگر در این دمو، تأکید بر مفهوم «بردارهای تعاملی» (cooperative vectors) است؛ مایکروسافت اخیراً توضیح داده که این بردارها به طور ویژه برای کارهای هوش مصنوعی بهینهسازی شدهاند و میتوانند سرعت رندر آنی را در بازیها بالا ببرند. در مجموع، آنچه در این نسخه بتا دیده میشود، نشان میدهد ترکیب معماری کارتهای گرافیکی انویدیا با قدرت شبکههای عصبی نهتنها میتواند گرافیک بازیها را غنیتر کند، بلکه محدودیتهای حافظه را از سر راه برمیدارد. هرچند هنوز راهی طولانی در پیش است تا توسعهدهندگان به صورت گسترده از NTC استفاده کنند، اما به نظر میرسد این فناوری قدمی اساسی در حل مشکلات فزاینده مربوط به محدودیت و هزینه حافظه گرافیکی باشد.








